 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImagine a City: CityGenAgent for Procedural 3D City Generation
Feb 05, 2026The automated generation of interactive 3D cities is a critical challenge with broad applications in autonomous driving, virtual reality, and embodied intelligence. While recent advances in generative models and procedural techniques have improved the realism of city generation, existing methods often struggle with high-fidelity asset creation, controllability, and manipulation. In this work, we introduce CityGenAgent, a natural language-driven framework for hierarchical procedural generation of high-quality 3D cities. Our approach decomposes city generation into two interpretable components, Block Program and Building Program. To ensure structural correctness and semantic alignment, we adopt a two-stage learning strategy: (1) Supervised Fine-Tuning (SFT). We train BlockGen and BuildingGen to generate valid programs that adhere to schema constraints, including non-self-intersecting polygons and complete fields; (2) Reinforcement Learning (RL). We design Spatial Alignment Reward to enhance spatial reasoning ability and Visual Consistency Reward to bridge the gap between textual descriptions and the visual modality. Benefiting from the programs and the models' generalization, CityGenAgent supports natural language editing and manipulation. Comprehensive evaluations demonstrate superior semantic alignment, visual quality, and controllability compared to existing methods, establishing a robust foundation for scalable 3D city generation.
More than Vanilla Fusion: a Simple, Decoupling-free, Attention Module for Multimodal Fusion Based on Signal Theory
Dec 12, 2023The vanilla fusion methods still dominate a large percentage of mainstream audio-visual tasks. However, the effectiveness of vanilla fusion from a theoretical perspective is still worth discussing. Thus, this paper reconsiders the signal fused in the multimodal case from a bionics perspective and proposes a simple, plug-and-play, attention module for vanilla fusion based on fundamental signal theory and uncertainty theory. In addition, previous work on multimodal dynamic gradient modulation still relies on decoupling the modalities. So, a decoupling-free gradient modulation scheme has been designed in conjunction with the aforementioned attention module, which has various advantages over the decoupled one. Experiment results show that just a few lines of code can achieve up to 2.0% performance improvements to several multimodal classification methods. Finally, quantitative evaluation of other fusion tasks reveals the potential for additional application scenarios.
Learning Audio-Visual embedding for Wild Person Verification
Sep 09, 2022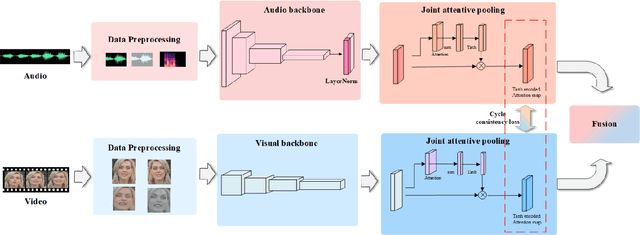
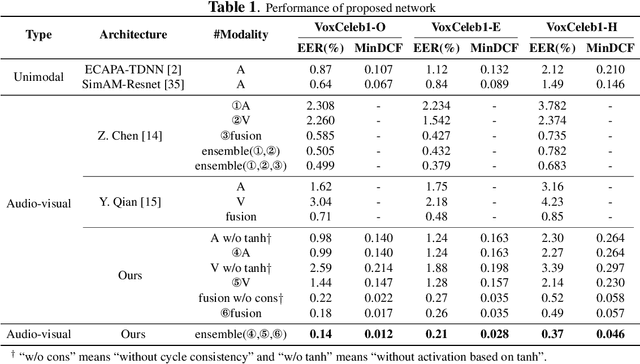
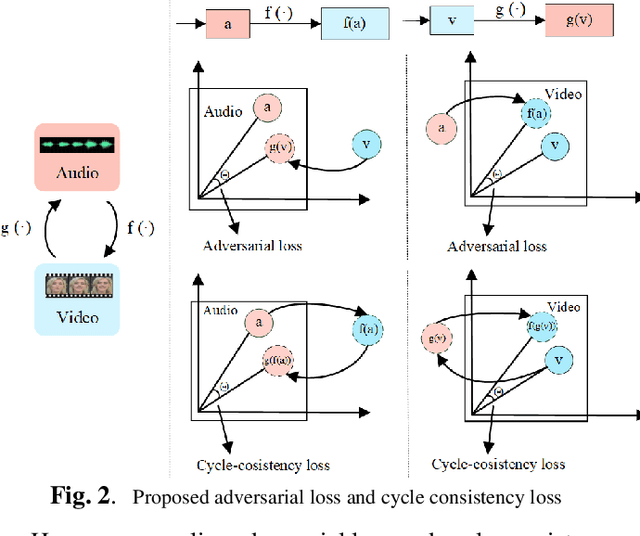
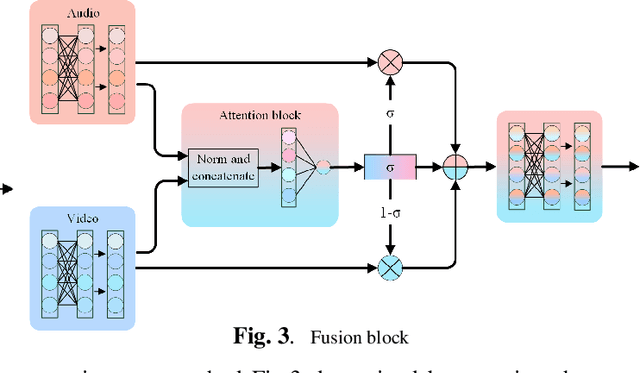
It has already been observed that audio-visual embedding can be extracted from these two modalities to gain robustness for person verification. However, the aggregator that used to generate a single utterance representation from each frame does not seem to be well explored. In this article, we proposed an audio-visual network that considers aggregator from a fusion perspective. We introduced improved attentive statistics pooling for the first time in face verification. Then we find that strong correlation exists between modalities during pooling, so joint attentive pooling is proposed which contains cycle consistency to learn the implicit inter-frame weight. Finally, fuse the modality with a gated attention mechanism. All the proposed models are trained on the VoxCeleb2 dev dataset and the best system obtains 0.18\%, 0.27\%, and 0.49\% EER on three official trail lists of VoxCeleb1 respectively, which is to our knowledge the best-published results for person verification. As an analysis, visualization maps are generated to explain how this system interact between modalities.